
In this article
- What "Extracting Data From a PDF" Actually Means
- Why Extracting Data From PDFs is Often Difficult
- Method 1: Extracting Data From Fillable PDF Forms
- Method 2: Extracting Data From Non-Form PDFs
- Method 3: Extracting Data From Scanned PDFs
- Automated PDF Data Extraction: What Can and Cannot Be Automated
- AI Data Extraction From PDFs: How It Changes The Process
- Using PDFelement To Extract Data From PDFs
- Extracting PDF Data to Spreadsheets and Other Tools
- AI vs. Workflow Tools (Power Automate and Similar)
- Common Mistakes in PDF Data Extraction
PDFs are part of daily work for most teams, from invoices to contracts to monthly summaries. Reading is straightforward, but turning those pages into usable spreadsheet data takes time. People end up copying totals and dates manually, and that is where the holdups happen. As document volume grows, the need to extract data from PDF files accurately becomes more urgent for operational efficiency and reporting clarity.
Therefore, organizations now explore manual, automated, and AI-powered methods to improve results. Each approach offers different levels of speed, flexibility, and control. Moreover, choosing the right method depends on document complexity and workflow demands.
Part 1. What "Extracting Data From a PDF" Actually Means
At first glance, opening a PDF and reading it may seem enough. However, viewing a document is very different from performing data extraction from PDF files. Extracting data, on the other hand, means capturing specific values, fields, or records and converting them into structured, usable formats such as spreadsheets or databases. The goal is not just to read content, but to transform it into actionable information.
Viewing vs. Extracting Data
When you view a PDF, you scroll through pages manually. You might copy and paste numbers or type them again elsewhere. In contrast, when you get data from PDF documents through extraction, the system identifies targeted information automatically. It detects invoice numbers, totals, dates, names, or table rows and places them into organized outputs. Extraction focuses on precision, repeatability, and usability rather than simple readability.
Structured vs. Unstructured PDF Data
Some PDFs follow predictable layouts with labelled fields and clear tables. These structured documents allow faster recognition of repeating data patterns. Other PDFs contain free text, irregular formatting, or scanned image content. Unstructured files require contextual interpretation of relationships between elements. Effective extraction adapts to both formats without sacrificing reliability.
Common Business and Research Use Cases
To make it feel real, the following use cases show where extraction saves effort:

- Invoice Sorting: Accounts teams pull totals, dates, and supplier names from invoices fast. This reduces retyping and delays in payments during busy periods.
- HR Paperwork: HR staff capture employee details from forms and signed documents easily. This keeps records consistent and helps during audits or policy checks.
- Contract Checking: Legal teams extract renewal dates, key clauses, and obligations from agreements. This speeds reviews and prevents missed deadlines or costly misunderstandings.
- Sales Updates: Sales teams lift customer details and pricing from proposals and quotes. This keeps CRM entries clean and improves forecasting for upcoming deals.
- Research Data: Researchers extract tables, references, and results from journal PDFs quickly. This supports faster analysis and cleaner notes for reports and publications.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
Part 2. Why Extracting Data From PDFs is Often Difficult
PDF files look clean and structured on the surface. However, they were originally designed to preserve layout, not to store data in a flexible, reusable format. A PDF focuses on keeping fonts, spacing, and design consistent across devices. That visual stability makes reading easy, yet it often makes data extraction from PDF files surprisingly complex.
PDFs Are Built for Layout, Not Data
Unlike spreadsheets or databases, PDFs do not always organize information into clear data fields. What appears to be a neat table might actually be separate text boxes positioned carefully on a page. As a result, systems must interpret visual placement before identifying meaningful values.
Different Types of PDFs Create Different Challenges
| PDF Type | What It Is | Main Challenge for Extraction |
| Digital PDF | Text is selectable and usually created from software exports. | Tables may be "visual," with columns built from spacing, not true structure. |
| Fillable PDF Form | Contains form fields for typing names, dates, and values. | Poorly designed fields, inconsistent naming, and hidden layers can confuse outputs. |
| Scanned PDF | A photo or scan saved as a PDF image. | Needs OCR first, and low-quality scans reduce recognition accuracy. |
Why One Method Never Works For All PDFs
Since formats vary so widely, a single extraction method rarely fits every scenario. A tool that works perfectly on digital reports may struggle with scanned receipts. Therefore, successful workflows often combine multiple techniques depending on document type and quality.
G2 Rating: 4.5/5 |100% Secure
Part 3. Method 1: Extracting Data From Fillable PDF Forms
Fillable PDF forms store entries inside named fields, not inside regular paragraph text. Each field keeps a label and a value, which makes information easier to collect consistently. This structure helps tools extract data from PDF forms with fewer formatting errors.
Exporting Form Data Directly
When a PDF includes real form fields, you can export those field values in minutes. Most PDF tools offer a form export option that creates a CSV, FDF, or XML file. After exporting, open the file in a spreadsheet and confirm columns match field names.
When This Method Works Best
This method works best when documents use the same form template every time. It suits surveys, applications, and checklists where every field is completed consistently. It performs poorly on scanned PDFs, images, or layouts without interactive fields.
Part 4. Method 2: Extracting Data From Non-Form PDFs
Non-form PDFs often contain data inside visible tables or aligned columns. These documents show structure visually, but the file may not store true fields. You can still capture values if rows and columns are consistent across pages.
Copy vs. Structured Extraction
Simple copy and paste works for small tables, but formatting breaks easily. Structured extraction tools try to keep rows, columns, and headers aligned correctly. When accuracy matters, structured extraction saves cleanup time in spreadsheets.
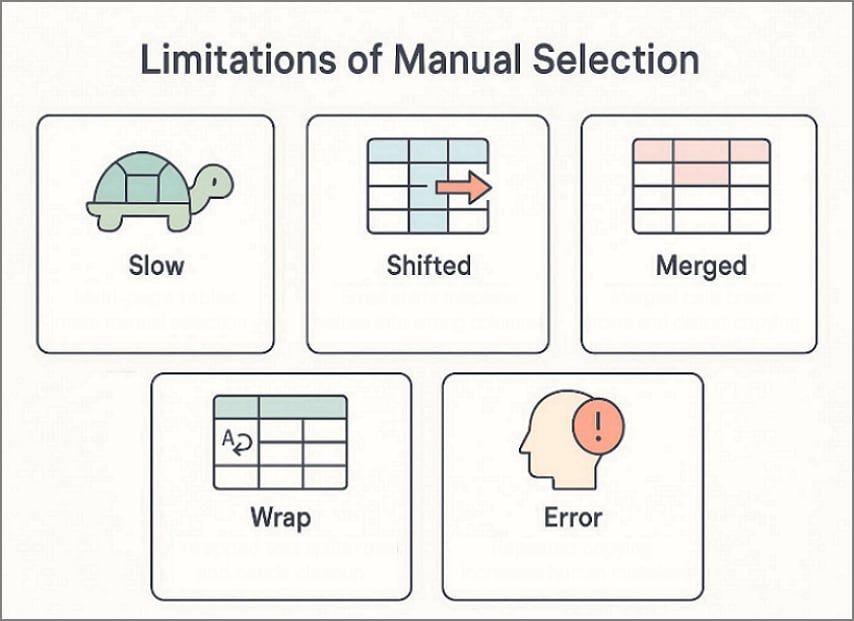
Limitations of Manual Selection
- Manual selection becomes slow when tables span multiple pages regularly.
- Small alignment shifts can push values into the wrong columns easily.
- Merged cells often break row structure and distort copied results.
- Wrapped text creates split rows that need extra cleanup later.
- Human error increases when you copy many tables repeatedly daily.
Part 5. Method 3: Extracting Data From Scanned PDFs
Scanned PDFs are usually page images, not selectable text inside the document. That is why software must read the image and convert it into text. Thus, OCR enables you to extract data from scanned PDF by recognising printed characters and layout patterns.
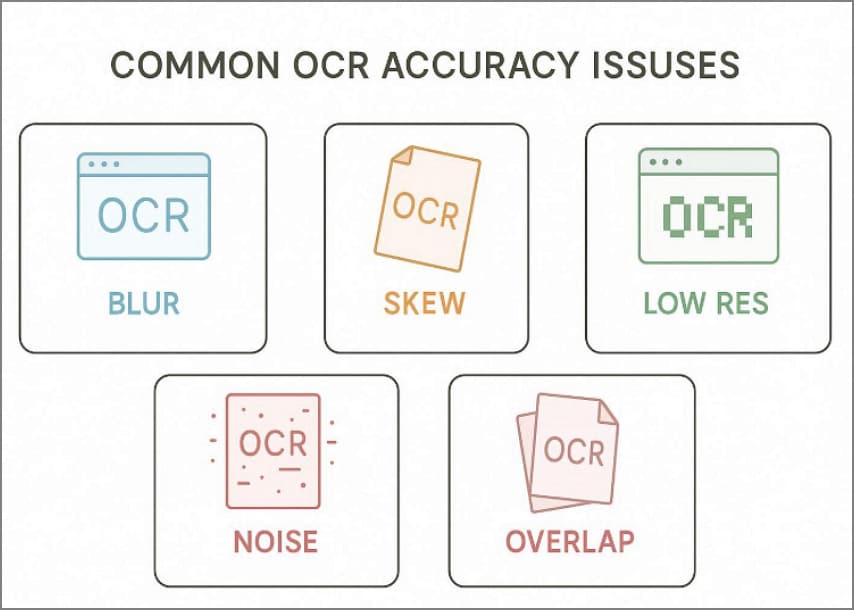
Common OCR Accuracy Issues
- Blurred scans reduce OCR confidence, making it harder to extract data from scanned PDFs.
- Skewed pages misalign text lines, causing incorrect words and broken table rows.
- Low-resolution images create jagged characters, so numbers are misread or merged.
- Shadows and background noise add artifacts, confusing punctuation, decimals, and field edges.
- Handwriting, stamps, and signatures overlap text, reducing accuracy and increasing manual fixes.
When Pre-Processing Improves Results
Pre-processing improves OCR when the scan quality is uneven or difficult to read. Steps like deskewing, de-noising, contrast boosting, and cropping margins reduce errors. If pages are rotated or curved, correction helps OCR detect lines and columns better.
G2 Rating: 4.5/5 |100% Secure
Part 6. Automated PDF Data Extraction: What Can and Cannot Be Automated
As organizations scale document processing, automated data extraction from PDF becomes an operational necessity. It reduces manual entry, shortens turnaround time, and improves consistency across recurring workflows. However, while automatic data extraction from PDFs significantly increases efficiency, it works best within defined boundaries. Understanding what can and cannot be automated helps set realistic expectations.
What Can Be Automated
Rule-Based Extraction
Rule-based extraction performs well with predictable document layouts. It captures values using fixed keywords, coordinates, or consistent field labels. Standardized invoices, internal templates, and recurring reports are ideal candidates. When structure remains stable, automation delivers fast and reliable outputs.
Batch Extraction Workflows
Batch workflows allow large volumes of similar PDFs to be processed together. Teams can upload multiple files and extract data in one automated cycle. This is effective for monthly invoices, claims, or vendor statements. High-volume environments benefit from speed and reduced repetitive handling.
Where Automation Breaks Down
Automation struggles when layouts vary widely across different document templates. Unstructured text, inconsistent formatting, and handwriting often reduce extraction accuracy significantly. Low-quality scans may require manual correction after OCR text recognition completes. Ambiguous fields demand contextual interpretation that fixed rules cannot provide reliably.
Part 7. AI Data Extraction From PDFs: How It Changes The Process
Traditional systems treat PDFs like fixed images with locked layouts. In contrast, AI data extraction from PDF changes document processing in practical ways. Instead of reading coordinates, AI evaluates structure, relationships, and contextual meaning. This shift turns extraction from mechanical capture into intelligent document understanding.
How AI Interprets Document Structure
AI analyzes spacing, alignment, font hierarchy, and content grouping together. It detects headings, tables, totals, and labels through structural cues. Rather than relying on fixed pixel locations, it studies logical relationships. As a result, extraction remains stable even when layouts shift unexpectedly. Have a look at the points below for what AI considers inside a document during interpretation:
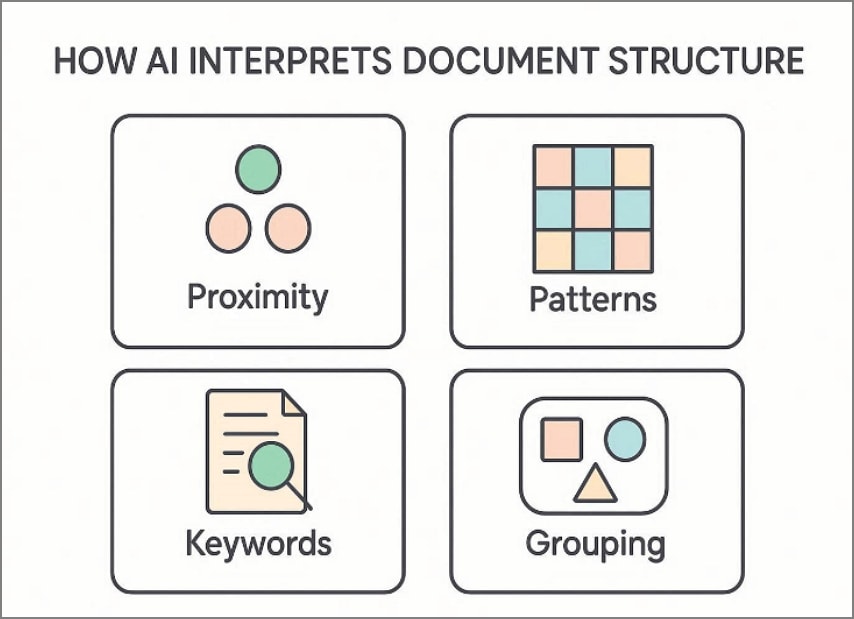
- Text proximity between labels and values across sections and columns.
- Repeated patterns that signal tables, line items, or structured lists.
- Surrounding keywords that clarify totals, taxes, dates, and identifiers.
- Visual grouping that connects related fields within the same context.
Extracting Meaning, Not Just Text
Older automation captured characters without understanding their business purpose. When tools AI extract data from pdf content, they interpret intent using context. For example, "Total" usually indicates the payable amount near that label. Context reduces confusion between invoice numbers and similar reference fields. Therefore, extracted outputs require fewer corrections during validation and reporting.
Using AI to Handle Inconsistent Layouts
In real workflows, vendors rarely maintain identical formatting standards consistently. Tables shift positions, headings move, and fonts vary across document versions. Thus, rule-based systems often fail when templates change without prior warning. Therefore, AI adapts by using relationships between labels and values, not coordinates.
| Rule-Based Extraction | AI-Based Extraction |
| Depends on fixed positions and rigid templates for field capture. | Uses structure and context to identify fields more reliably. |
| Breaks when layouts change slightly across suppliers and versions. | Stays usable when columns shift or headings move locations. |
| Captures text strings without interpreting meaning within the document. | Extracts meaningful values by understanding labels and relationships. |
Part 8. Using PDFelement To Extract Data From PDFs
PDFs look tidy, but extracting clean data often becomes frustrating fast. Forms may export fields, tables may break, and scans need accurate OCR. Instead of switching tools, many teams prefer one workflow for everything. That is where PDFelement fits, helping you extract data from PDF form fields and other layouts.
Moreover, users can reliably pull data from fillable forms, tables, or scanned pages. Then you can review results, export structured files, and repeat the process faster.
Extract Data From PDF Forms and Tables
Fillable PDF forms store responses inside named fields, not plain text blocks. Table PDFs look structured, yet they usually lack export-ready field tags entirely. PDFelement captures both by exporting fields or extracting selected tables fast. So, use it for invoices, applications, and reports where columns and labels repeat consistently across files. Follow the stepwise guide below to export clean data and check results:
G2 Rating: 4.5/5 |100% Secure
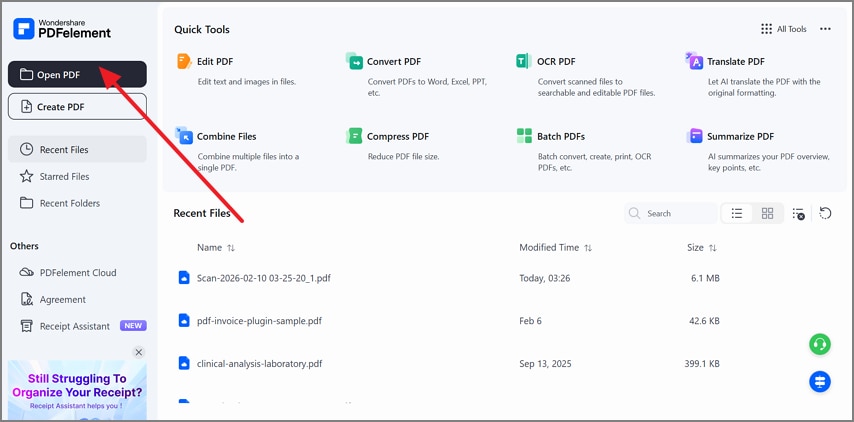
Step 1Open the PDF in PDFelement to Proceed
To begin, launch PDFelement and select "Open PDF" from the main dashboard.
Step 2Extract Data with Form Tool
Next, navigate to the "Form" option in the left sidebar and select "Three Dots" to proceed. From the dropdown menu, choose "Extract Data" to begin the structured data capture process.
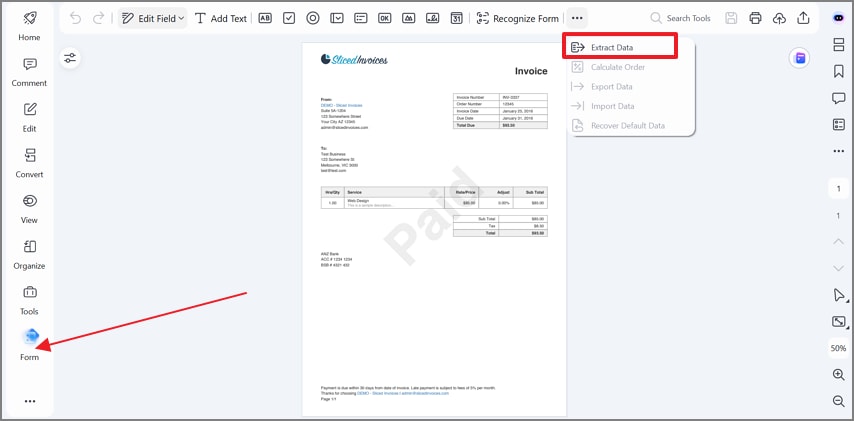
Step 3Choose the Extraction Mode
At this stage, choose "Extract data based on the selection" in the extraction dialog box and press "Apply." This mode allows precise control by extracting only the fields you manually select.
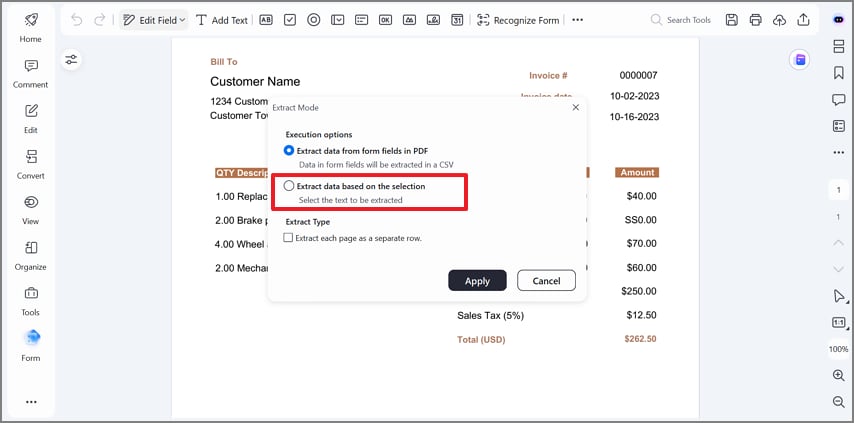
Step 4Mark Required Fields and Apply Extraction
After selecting the mode, draw selection boxes around required fields such as line items, totals, or tax values, and click the "Apply" button.
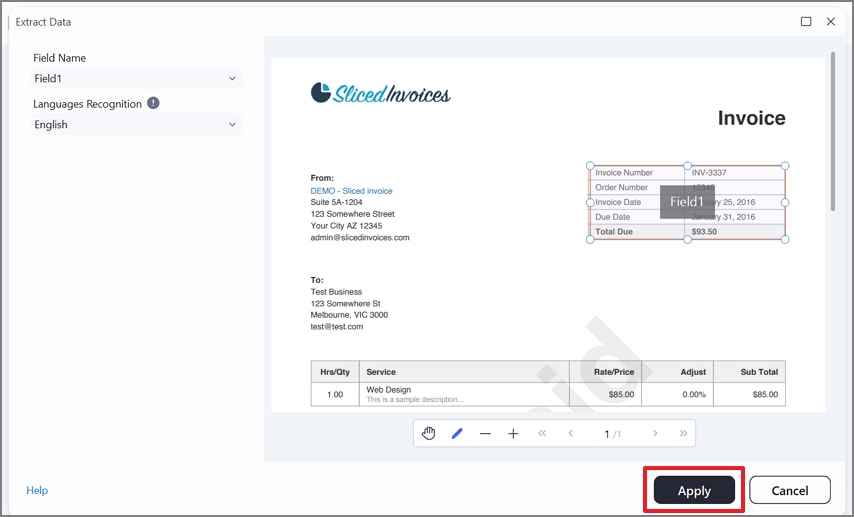
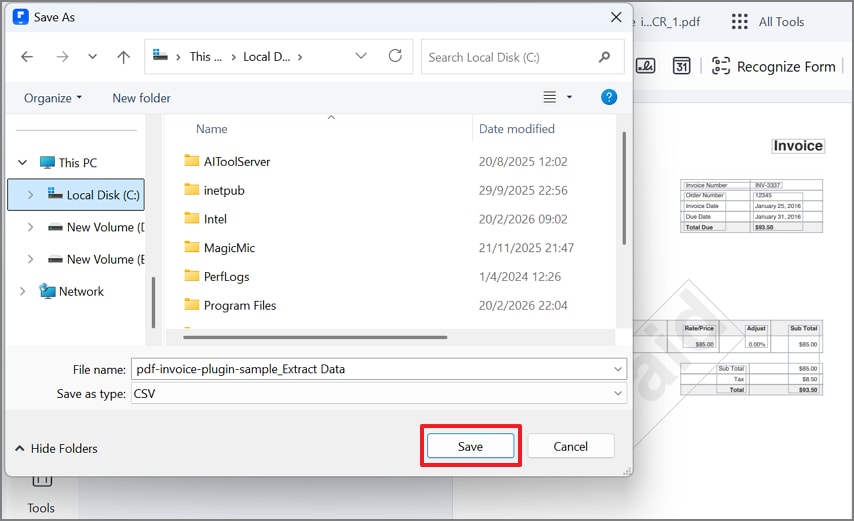
Step 5Export Extracted Data as CSV and Save
Upon selecting "Apply", PDFelement opens the Save As dialog box automatically. Now, select the desired export format, such as CSV, and press "Save" to export extracted data to your device.
OCR-Based Extraction For Scanned PDFs
Scanned PDFs are images, so you cannot copy text directly from them. OCR converts the image into selectable text, improving search and extraction accuracy. Thus, better scans produce better results, especially for tables and numbers today. Pre-processing fixes skew, blur, and noise, which reduces errors during recognition and export later. Adhere to the steps below to try this method with PDFelement:
Step 1Access the OCR Tool to Continue
First, open the scanned PDF in PDFelement and click "OCR" on the top toolbar.
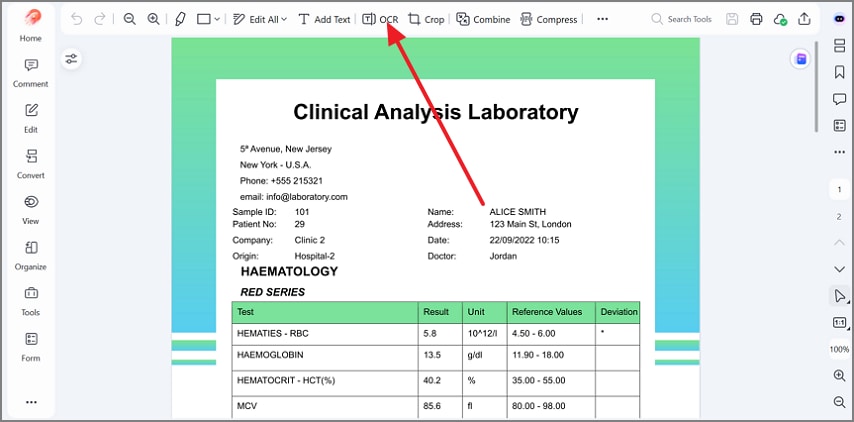
Step 2Pick Editable Text and Apply OCR
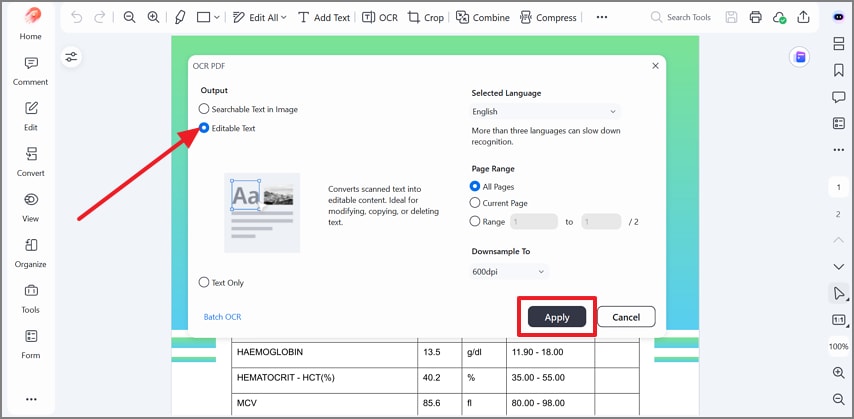
Next, select "Editable Text" in the OCR window, then confirm the language and page range. After that, press "Apply" to convert the scan into editable, selectable text.
G2 Rating: 4.5/5 |100% Secure
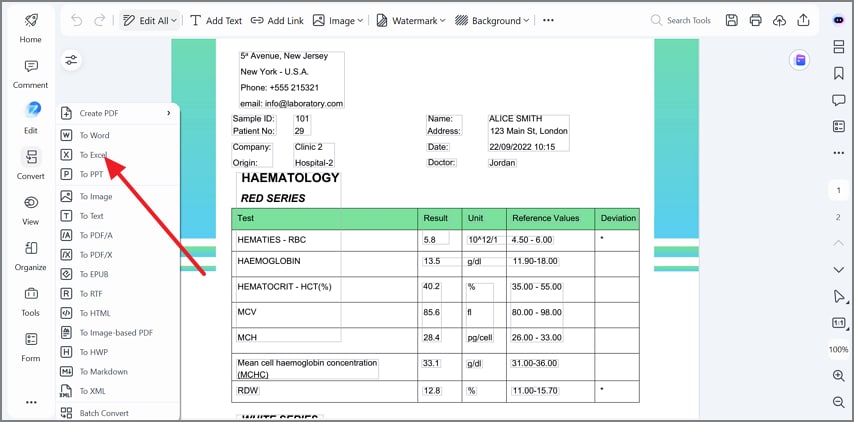
Step 3Convert the OCR File to Excel Format
Then, go to "Convert" and choose "To Excel" from the dropdown menu. This prepares table data for spreadsheet extraction and structured editing.
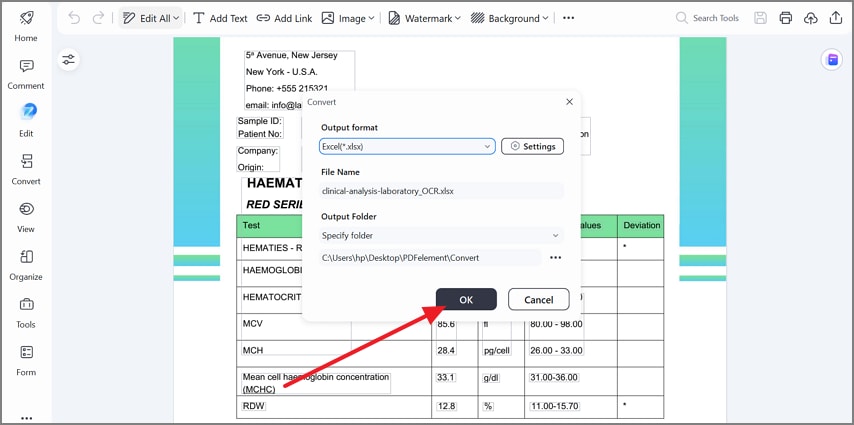
Step 4Save as XLSX and Verify Spreadsheet Accuracy
Finally, keep "Excel (*.xlsx)" as the output format, choose an output folder, and click "OK." Afterwards, open the exported sheet and quickly check columns, totals, and units for accuracy.
Batch Extraction For Repeated Layouts
Batch extraction processes many PDFs at once, using one repeated selection pattern. It works best when documents share the same template and page structure. You define regions once, then apply them across the whole folder. This approach speeds monthly reporting, invoice runs, and audits while maintaining consistent columns for analysis. Next, follow the steps mentioned below to see how this method works:
Step 1Locate All Tools to Access Batch Features
To start, launch PDFelement and choose "All Tools" to proceed further.
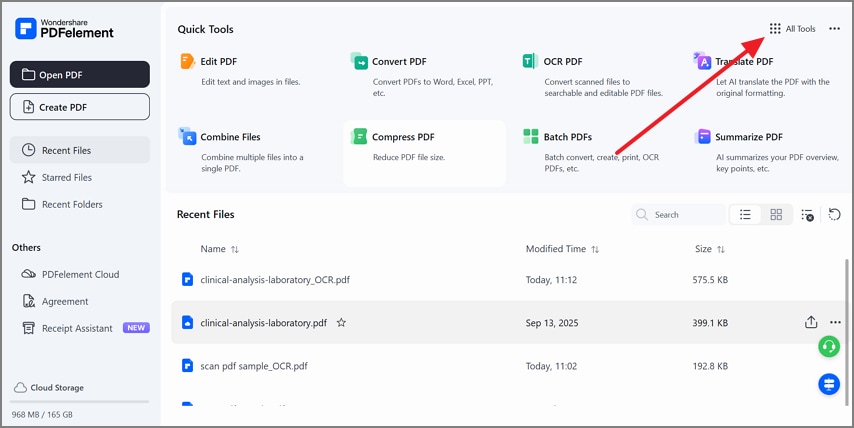
Step 2Select Batch Extract Data in Batch Process
Afterwards, in the "Batch Process" window, choose "Batch Extract Data" to start the bulk extraction tool.
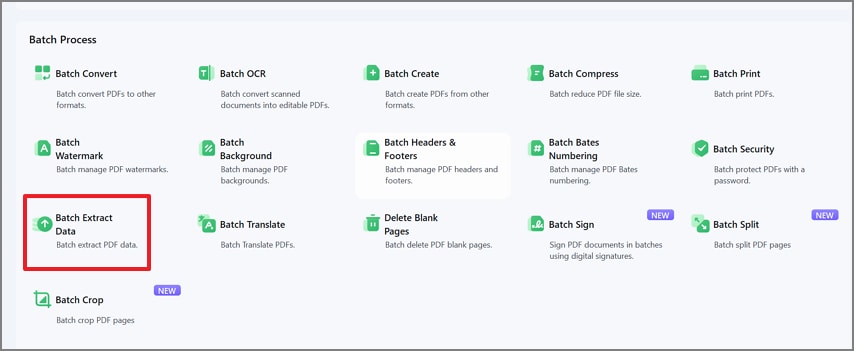
Step 3Add PDFs and Set Extraction Output Options
Then, press the "Add Files" option and load your PDFs in one go. On the right panel, pick "Extract data from PDF form fields" or "Extract data from marked PDF," choose the export style, and confirm the output folder.
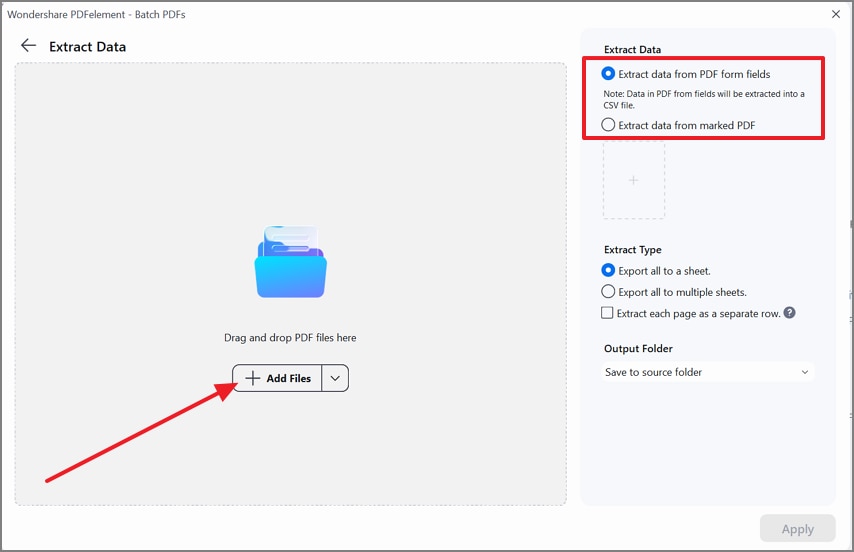
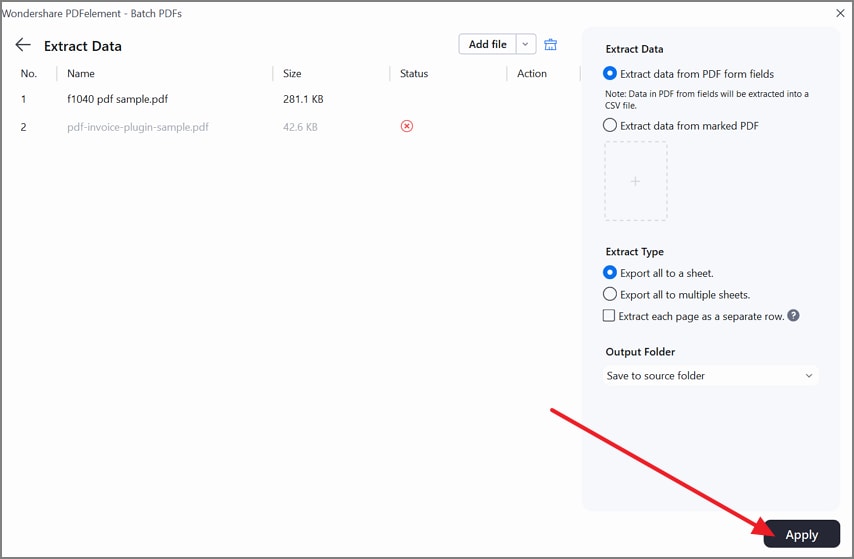
Step 4Apply Batch Extraction and Validate Output Columns
Lastly, select the "Apply" button to generate the output sheet. After that, access the exported file and quickly verify key columns match across documents.
G2 Rating: 4.5/5 |100% Secure
AI Features
After you extract data from a PDF to Google Sheets, the AI features mentioned below help verify and reuse results faster:
Chat with PDF: Ask instant questions about totals, dates, vendors, and missing fields inside PDFs. It highlights supporting lines so you can verify numbers before sharing results.
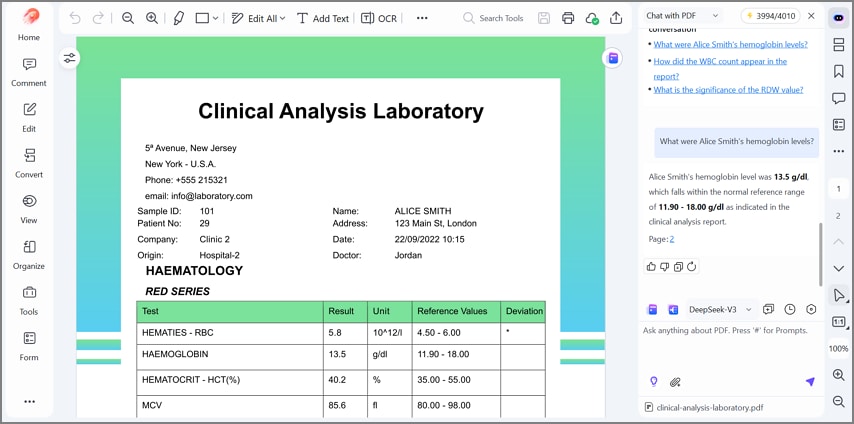
AI Summarize: Summarise long PDFs into key points, decisions, and important numbers quickly and clearly. It explains tables, flags trends, anomalies, and items needing human review promptly.
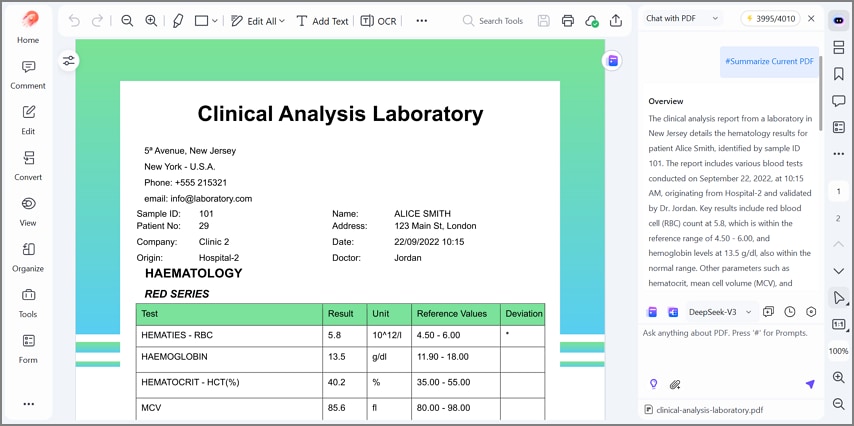
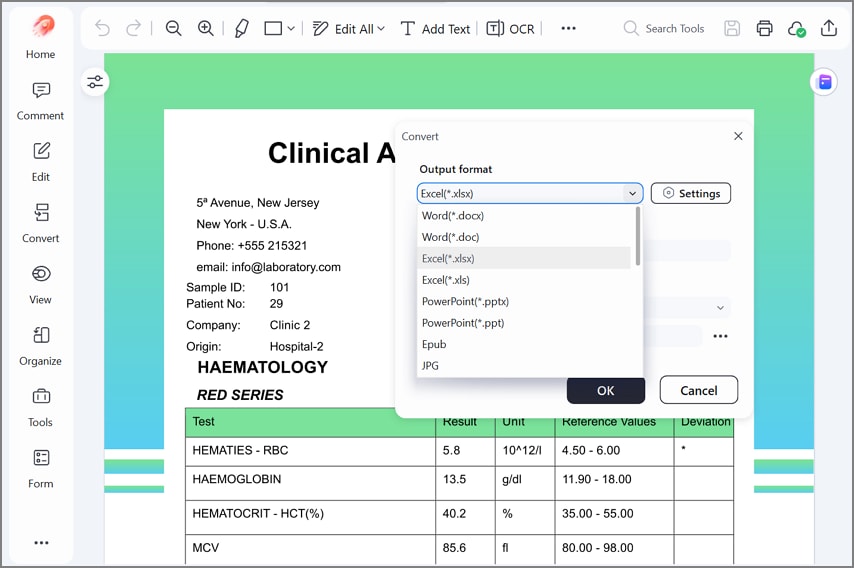
Export Structured Results For Reuse: Export outputs as CSV or Excel with stable headers for reuse anywhere. Consistent structure reduces cleanup and supports reporting, automation, and future imports smoothly.
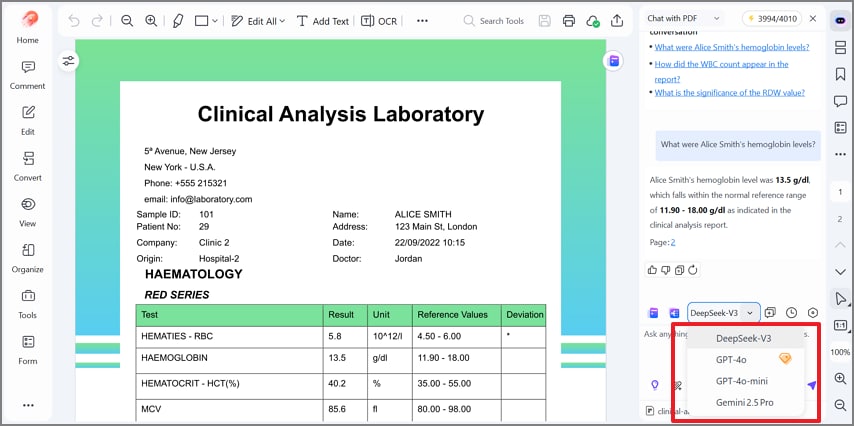
Switch AI Models: Switch between GPT-4o, Gemini, and DeepSeek to cross-check answers reliably every time. Comparing outputs boosts confidence, catches errors, and reduces single-model blind spots fast.
Part 9. Extracting PDF Data to Spreadsheets and Other Tools
Export options turn extracted tables into spreadsheets that teams can validate quickly. You can extract data from a PDF to Google Sheets by exporting CSV, then importing it. Excel exports work well for offline cleanup, formulas, and pivot-based reporting tasks.
- Choose CSV or XLSX when you need reliable columns and headers preserved.
- Import the file into Sheets, then freeze headers for easier scanning.
- Apply data types for dates and currency to prevent sorting mistakes later.
Preparing Extracted Data For Further Automation
Automation needs consistent columns, stable headers, and predictable row structures every time. Start by renaming fields clearly, then remove duplicates created by repeated headers.
- Standardise date and decimal formats to prevent scripts from failing unexpectedly.
- Add a unique ID column, enabling safe merges across multiple files.
- Validate totals against the PDF, then flag outliers for quick review.
Why Clean Extraction Matters Downstream
Messy extraction creates silent errors that spread into reports, dashboards, and payments. Clean outputs reduce rework, speed approvals, and improve audit trails across departments.
- Clean tables improve matching in CRMs, ERPs, and finance reconciliation workflows.
- Accurate columns reduce manual fixes when connecting to Power Automate flows.
- Consistent data supports faster decisions because KPIs stay comparable over time.
Part 10. AI vs Workflow Tools (Power Automate and Similar)
AI tools focus on understanding and cleaning documents, while workflow tools focus on routing and automation. When people ask how power automate extract data from PDFs, the real answer is simple. Power Automate can move files and trigger actions, but the extraction quality still decides success.
What Power Automate Can Do Well
- Routes PDFs from email, OneDrive, and SharePoint into standardized workflows automatically and securely.
- Triggers approvals, alerts, and logging whenever new PDF documents arrive reliably today.
- Moves extracted values into Excel tables, databases, or CRM fields without retyping.
- Schedules recurring flows, ensuring consistent processing across teams and time zones daily.
Why Extraction Quality Still Matters
- Automation amplifies errors; one wrong digit can distort downstream reporting significantly more quickly.
- Shifted columns and merged cells break field mapping, causing misplacements often silently.
- Poor OCR misreads totals, increasing exceptions, manual fixes, and reconciliation delays later.
- Clean extraction improves audit trails, compliance checks, and confidence in decisions overall.
When PDF Data Must Be Prepared Before Automation
- Template Ready: Before Power Automate, extract data from PDF, standardize templates, and field names consistently.
- Scan Cleanup: Scanned PDFs need deskewing and contrast improvements before running OCR reliably.
- Table Hygiene: Messy tables require normalized headers and fixed row breaks for consistent structure.
- Layout Control: Variable layouts often need pre-extraction in a PDF tool before automation.
Part 11. Common Mistakes in PDF Data Extraction
Before starting how to extract data from pdf files, avoid assumptions that cause costly errors. The common mistakes below explain why accuracy drops and rework increases quickly:

- Same Treatment: Many teams treat every PDF format as identical, which causes extraction failures. Different PDF types need different methods for consistent and accurate results.
- OCR Dependence: Teams rely on OCR alone, even when text quality is low. Without review, OCR errors quickly spread into reports and financial records.
- Automation Expectation: Some expect complete automation, assuming AI will handle every exception reliably. In reality, unusual layouts and missing fields still require human judgment.
- Validation Neglect: Many skip validation checks, so incorrect totals and dates pass unnoticed. Basic rules and cross-checks improve accuracy before exporting results downstream.
- Tool Mismatch: Organizations choose tools without evaluating document complexity and variability properly. Poor tool selection leads to inconsistent outputs and frequent manual corrections.
People Also Ask
-
How do I extract data from a PDF?
Use a PDF tool to select tables, export form fields, or run OCR when needed. Then verify columns, fix row breaks, and save clean results as CSV or Excel files. -
Can AI extract data from scanned PDFs?
Yes, AI can extract data from scanned PDFs after OCR converts images into searchable text. Accuracy improves with clear scans, correct language settings, and careful validation of key numbers afterward. -
What is the best PDF data extraction tool?
The best tool matches your files, offering form export, table extraction, OCR, and batch processing. If you need one workflow, PDFelement combines extraction, OCR, and spreadsheet export in one place. -
Is automated PDF data extraction reliable?
Automated PDF extraction is reliable when layouts stay consistent, and scans remain clear across batches. It becomes less reliable with mixed templates, merged tables, handwriting, or format changes over time. -
How do I extract data from PDFs into spreadsheets?
Export extracted data as CSV or XLSX, then open it in Excel or Google Sheets. Clean headers, set data types, and validate totals so formulas and automations work correctly later.
Wrap-up: Choosing the Right PDF Data Extraction Approach
Choosing the best extraction approach starts with identifying your PDF type first. Forms export fields cleanly, while tables need structured selection for accuracy. Scanned documents require OCR before extraction to produce reliable results consistently. Automation and AI reduce effort, but review prevents downstream mistakes later. When collaborating, extract data from PDF to Google Sheets after cleaning headers. For a consistent workflow across cases, PDFelement remains a practical choice.

