
PDFelement-Powerful and Simple PDF Editor
Get started with the easiest way to manage PDFs with PDFelement!
Python is an easy-to-use and efficient programming language that is especially popular in text and image processing. With a vast number of libraries available, Python can automatically complete various types of tasks for you, including extracting text from images using OCR. Optical Character Recognition (OCR) is a technology that can recognize printed or handwritten characters on images and extract the characters.
This article describes how to use two popular OCR engines to extract text from images in Python.
In this article
How to Extract Text From Images Using Python
Extract Text From Images in Python Using Tesseract
Tesseract is a popular open-source OCR engine that has been pre-trained to support more than 100 languages. In this article, we use Python-tesseract (pytesseract), a Python wrapper for Tesseract that allows you to use Tesseract with Python. All steps described in this article are performed on a Windows PC.
Step 1 Download and install Python.
Python 3.6+ is required to use pytesseract. So, make sure to install a version later than 3.6. Then, in the installation window, select Add Python X.XX to PATH to automatically add Python to your system path. Otherwise, you must manually configure the system path after installing Python.
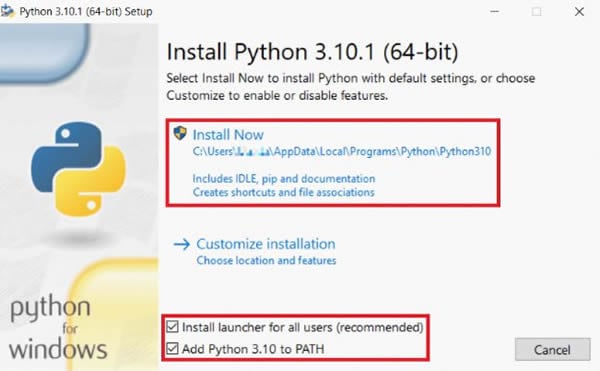
Install Python
Step 2 Download and install Tesseract.
You can download the latest installation package of Tesseract for Windows. Next, select the additional languages and scripts you want to install in the installation window. By default, you can only install the English language.
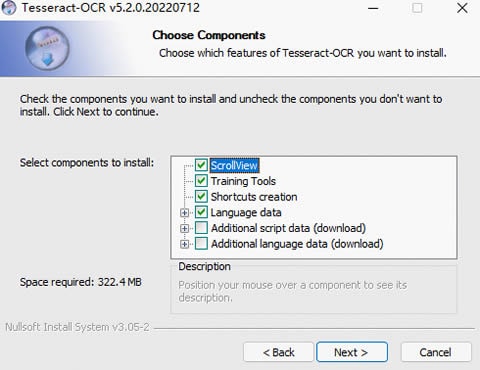
Install Tesseract
Tesseract provides a handy command-line tool that you can use to perform OCR on images. After you install Tesseract, open a CLI window, navigate to the folder where the image file whose text you want to extract is located, and run the following command:
tesseract out
This command extracts text from the specified image and saves the text in the out.txt file. To use Tesseract with Python, proceed to the next step to install the required Python packages.
Step 3 Install the Pillow and pytesseract packages.
Pillow is used to process images, and pytesseract is required to use Tesseract with Python. You can install the packages by running the following commands in a CLI window:
pip install pillow
pip install pytesseract
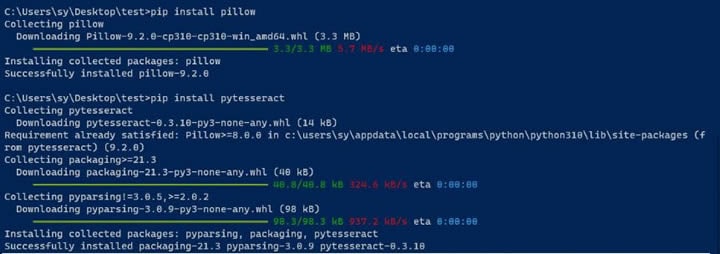
Install Python Packages
Step 4 Write Python code to extract text from images.
Once you install the packages, you are now ready to write your Python code to extract text from images. Go to the folder where the image files you want to extract text are stored. Create a text file and change its name to extract.py. You can change the text file to any name, but make sure that the file name extension is py.
Use a text editor such as Notepad to open the extract.py file. Copy the following sample code to the file and save the file:
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string(Image.open('test.jpg')))
To run the preceding script successfully, you must have an image file named test.jpg in the same folder as the extract.py file. This article uses the following image as an example.

OCR Test Image
Open a CLI window, go to the folder where the image file is located, and then run the following command:
python extract.py
You should get the following command output.
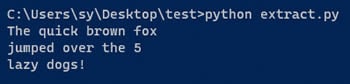
Tesseract Result
The output shows that the text is successfully extracted from the image. This concludes the basic process of using Tesseract with Python. For more information about how to use pytesseract, see its documentation.
If you want to extract text from multiple images in a batch, a simple way is to add the names of the files to a TXT file, such as images.txt. For example:
test.jpg
test1.jpg
Then, modify the extract.py file as follows:
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string('images.txt'))
When you run the preceding script, the text is extracted from all the images that are specified in the images.txt file.
Extract Text From Images in Python Using EasyOCR
EasyOCR is a Python package that provides a ready-to-use OCR engine and supports 80+ languages. EasyOCR is easy to install and very straightforward to use. This makes it a great solution for performing OCR with Python. You only need to install the PyTorch (required on Windows only) and EasyOCR packages, and then you can start extracting text from images using Python.
Step 1 Install the required Python packages.
To use EasyOCR on Windows, you must install the PyTorch and EasyOCR packages. Run the following commands in sequence to install the packages:
pip install torch torchvision torchaudio
pip install easyocr
Step 2 Write Python code to use EasyOCR.
Go to the folder where your image is located, create a .py file, such as extract.py, and then copy the following sample code to the file:
import easyocr
reader = easyocr.Reader(['en'])
result = reader.readtext('test.jpg', detail = 0)
print(result)
The following figure shows the command output when you run the extract.py file.

EasyOCR Result
As shown in the command output, the text is extracted from the test image.
Advantages and Disadvantages of Using Python
Python is a programming language that is easy to learn and use. It is widely used in deep learning and natural language processing. Compared with other languages, Python code is often simpler and shorter. However, it takes time to learn Python, and you need to research the OCR engines you want to use with Python.
Advantages of using Python to extract text from images:
- OCR engines such as Tesseract and EasyOCR are free to use.
- Python is suitable for batch and repetitive OCR tasks.
- It is efficient and fast to process a large number of images by using Python.
- You can obtain sound conversion results by tweaking the OCR engine options ts.
- You can save your well-designed Python script and use it whenever you need to extract text from images. You can also share the script with others who have the same conversion requirements.
Disadvantages of using Python to extract text from images:
- Python knowledge is required.
- Research must be done on the OCR engines that you want to use.
- Open-source OCR engines may not be as accurate as commercial ones. In addition, some may not be able to recognize handwriting.
Nonetheless, it is always good to learn something new. In addition, you can always switch to other tools when needed. There are plenty of existing tools that can help you quickly extract text from images. You can pick one based on your requirements.
How to Extract Text From Images without Python
If you are not a fan of programming and are looking for an out-of-the-box tool, Wondershare PDFelement - PDF Editor Wondershare PDFelement Wondershare PDFelement is a quick and easy app that you should check out.
PDFelement is a fast and all-around PDF editor that allows you to view, edit, and convert PDFs. PDFelement is also equipped with an advanced OCR engine, which can be used to extract text accurately and efficiently from images.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
PDFelement OCR
You can follow these steps to extract text from images in PDFelement:
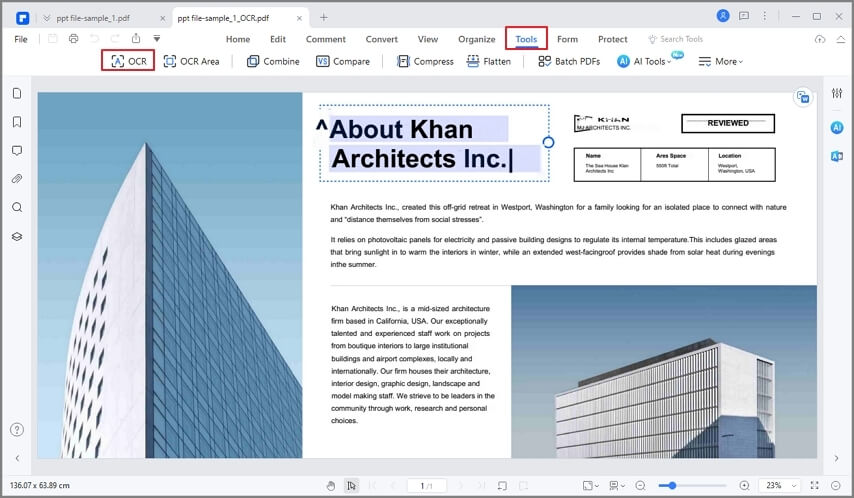
Step 1 Open PDFelement. Drag and drop the image file from which you want to extract text into the PDFelement window. You can also choose Create PDF > From File and select the image file. Then, PDFelement converts the image to a PDF and opens it in a new tab.
Step 2 In the Tools menu, click OCR to extract text from image. This allows PDFelement to recognize all characters in the image and turn them into editable and searchable text.
Step 3 Copy the text to the desired location and edit the text. You can also convert the PDF with editable text to other formats, such as Word or Excel.
In addition to the OCR engine, PDFelement also provides other features that can help improve your productivity:
- Open and view PDF files at a fast speed
- Edit content in PDF files, such as text and images
- Convert PDFs to various formats, such as EPUB and Word
Conclusion
Python is an excellent programming language that is suitable for automating repetitive tasks. By using Python, you can extract text from images easily and fast with open-source OCR engines. This article provided ways to invoke the OCR capabilities of Tesseract and EasyOCR using Python.
However, extracting text from images using Python involves programming, which requires basic programming knowledge and the Python language. If you don't have programming knowledge, many other options exist to complete text extraction from images. A great option to consider is PDFelement, an advanced and sophisticated application that can help you extract text from images easily and efficiently.

